
Ollama v0.19
Massive local model speedup on Apple Silicon with MLX
Gallery
About
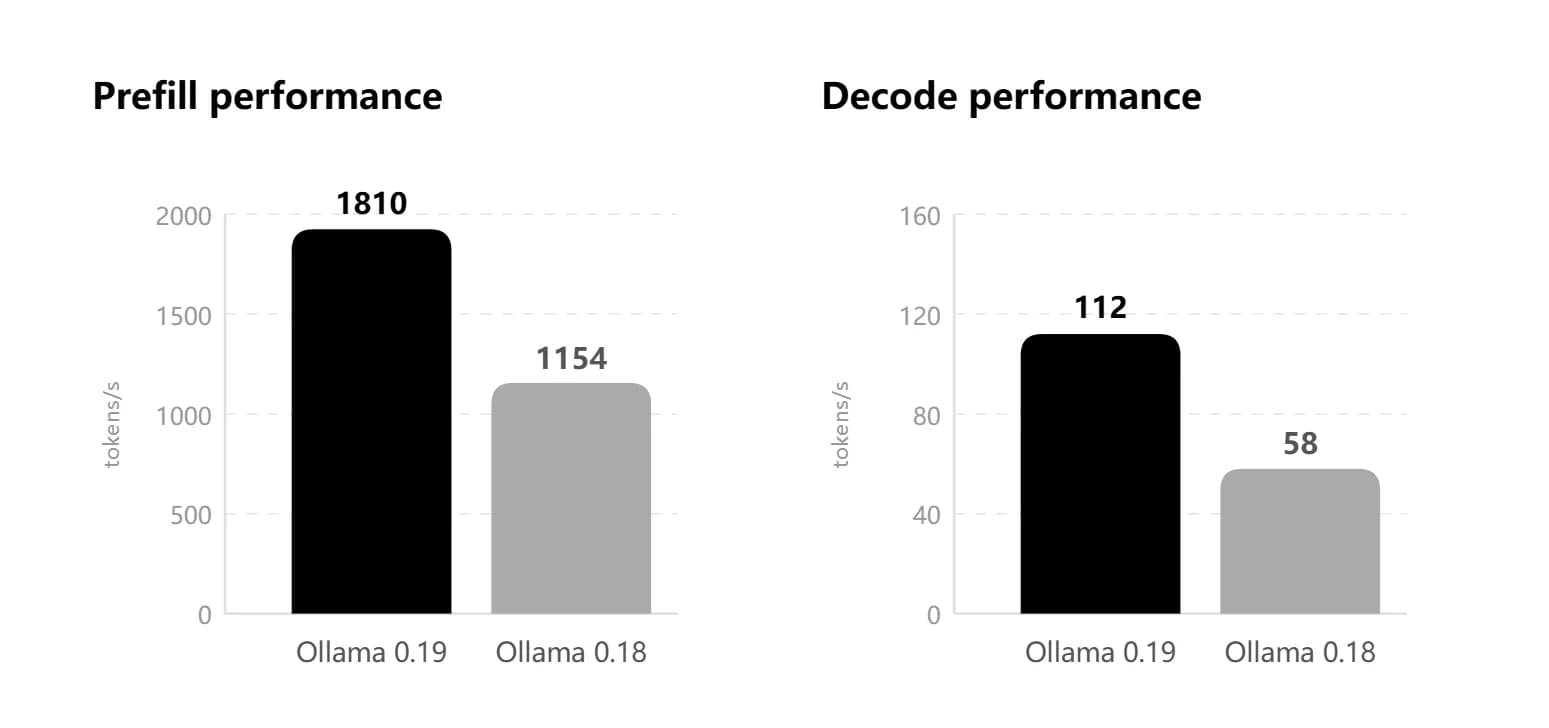
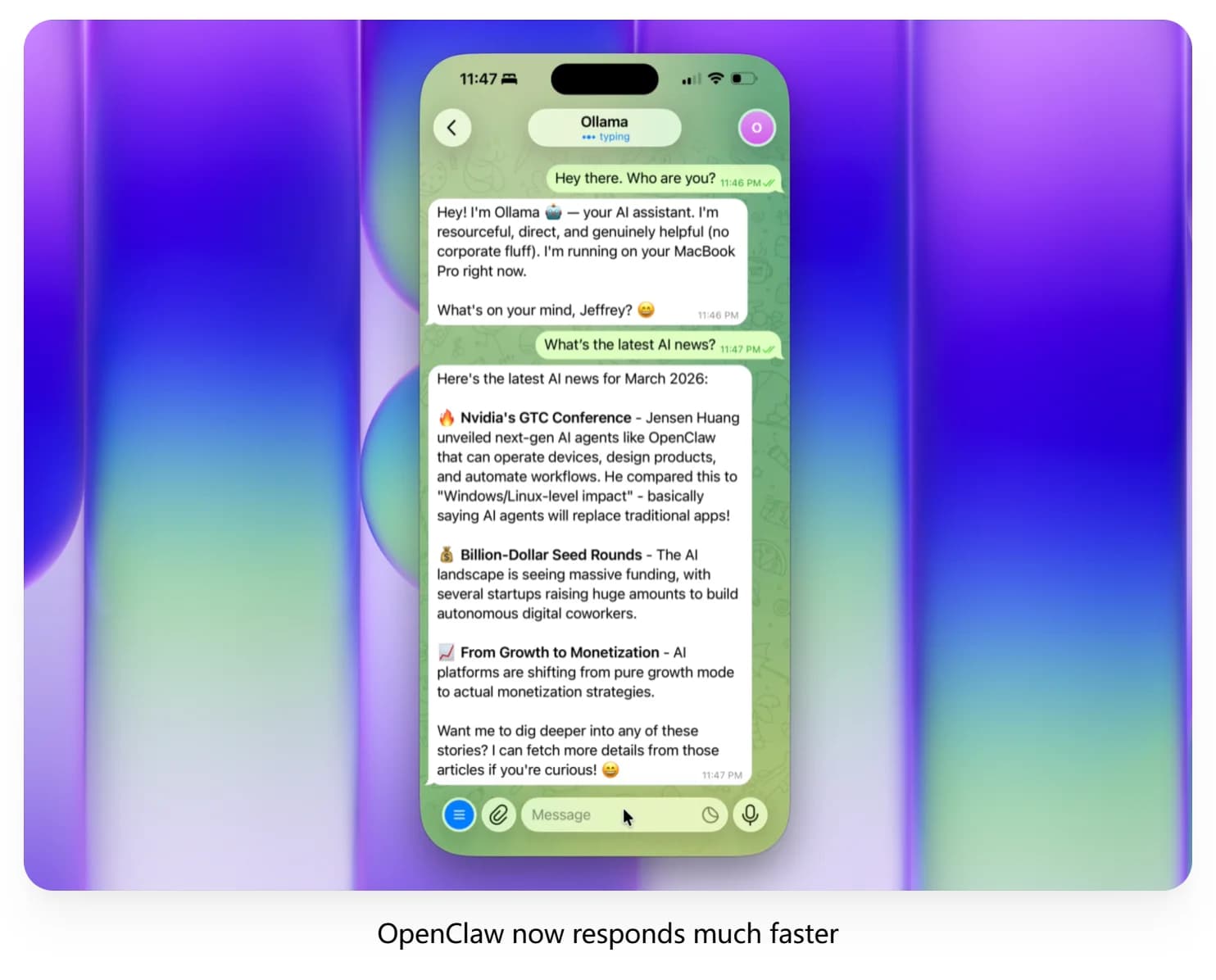
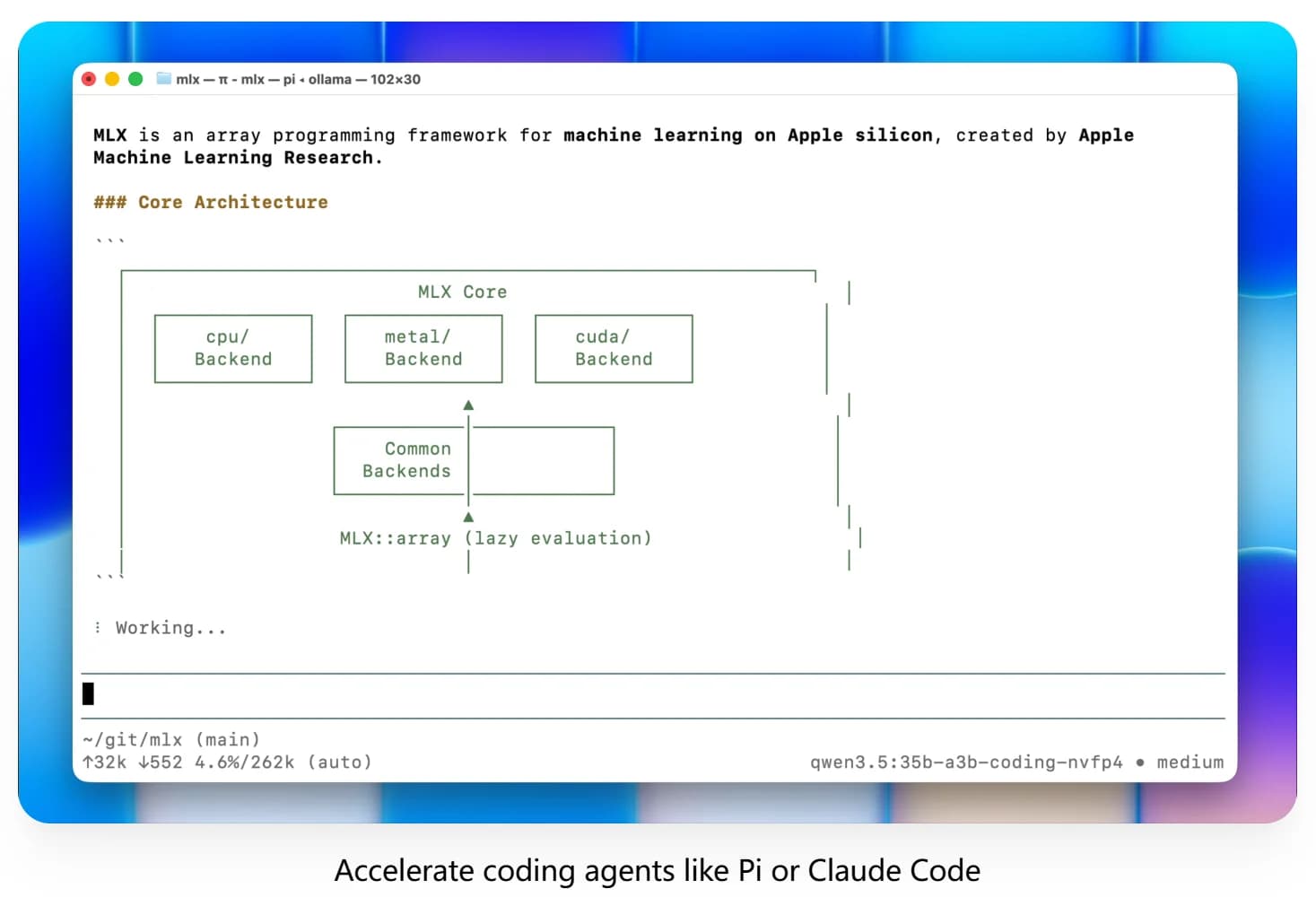
Ollama v0.19 rebuilds Apple Silicon inference on top of MLX, bringing much faster local performance for coding and agent workflows. It also adds NVFP4 support and smarter cache reuse, snapshots, and eviction for more responsive sessions.
Discussion (0)
Log in to join the discussion
No comments yet. Be the first to share your thoughts!