
General Compute
AI models that run on an inference cloud optimized for speed
Gallery



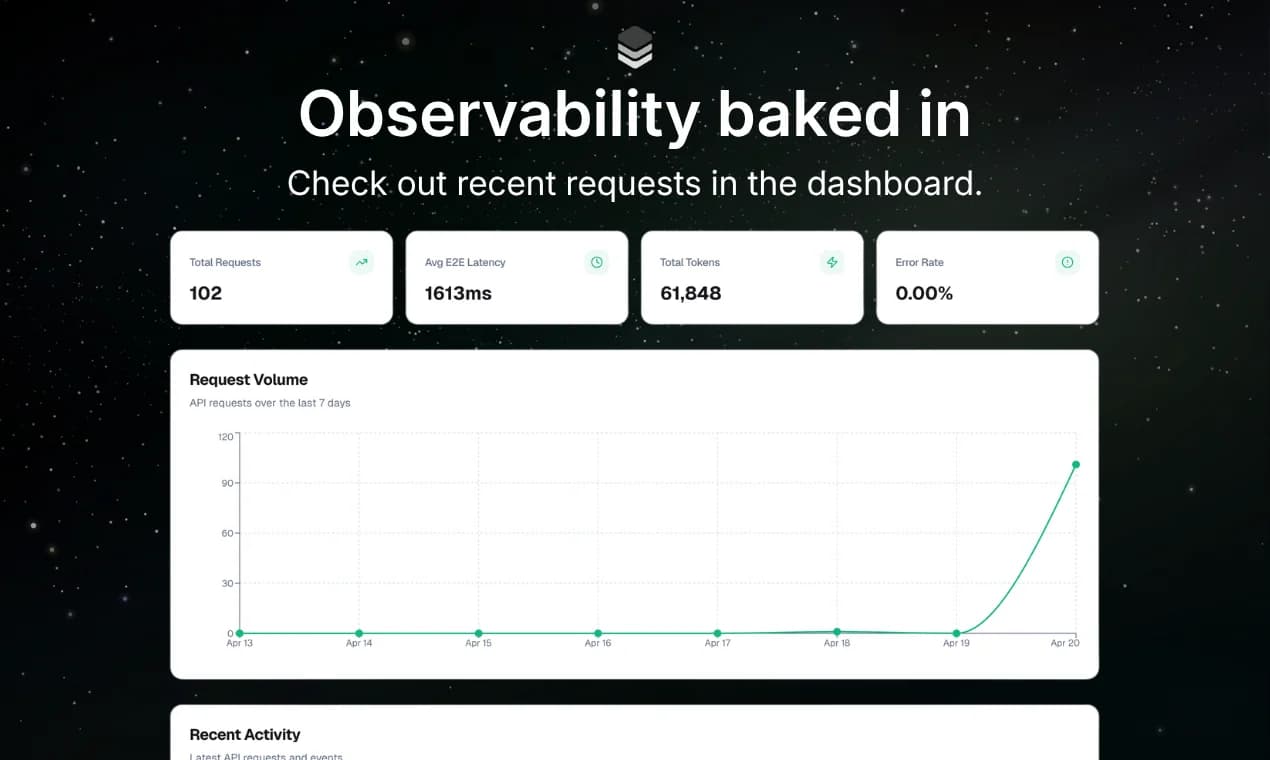
About
GPUs are built for training, not inference. General Compute is an inference cloud running on ASICs — purpose-built alternatives to Nvidia silicon designed specifically for inference. We deliver 5x faster responses and higher per-user throughput for latency-sensitive workloads like coding and voice agents. Our OpenAI-compatible API means you swap your base URL, keep your existing workflows, and run real-time AI on infrastructure built for the job.
Discussion (0)
Log in to join the discussion
No comments yet. Be the first to share your thoughts!